
Visual BankがAI開発向けの高品質データセットを発表しました!




Visual Bank、AI開発用データセットを新たに提供
Visual Bank株式会社は、AI学習用データソリューションであるQlean Datasetを通じて、さまざまな業務上の書類や帳票のデータセットを開始しました。この新しいデータセットは、主に大規模言語モデル(LLM)、光学文字認識(OCR)、およびマルチモーダルAIの研究と開発に役立ちます。
データセットの概要
このデータセットは、AIデータレシピと呼ばれるQlean Datasetの製品ラインに新たに加わるもので、以下のような実際のビジネスシーンで利用される書類が含まれています。
- - 履歴書
- - 職務経歴書
- - 領収書
- - 申込書
- - アンケート
現在のAI開発における必要性
近年、生成AIや自動業務化AIが導入される実態の中、企業内に保管されている非構造的な文書データをどのように詳細に理解し処理するかが重要な課題となっています。文書には個人情報や契約情報が含まれることが多いため、AIに学習データとして利用する際は、権利や取り扱いについて注意が必要です。
このQlean Datasetでは、そのための慎重な設計が施されています。特別に整理された業務ドキュメントを使用し、学習や評価に必要なデータを提供します。これにより、文書理解モデルの構築や情報抽出の精度検証を実施することができるのです。
ユースケースと研究目的
このデータセットは、次のような研究や実用目的で幅広く活用されます:
- - 文書理解モデルの研究
- - 情報抽出および質問応答モデルの検証
産業用途の拡大
業務書類の処理を行うAIシステムの開発においても、Qlean Datasetは重要な役割を果たします。特に領収書や申請書を対象としたOCRやインテリジェントドキュメントプロセシング(IDP)システムにおける、テキスト認識や情報抽出のフルプロセスの開発検証が行えます。
また、社内文書検索AIや業務支援チャットボットにおいて、このデータセットは業務文書を入力として利用した際の理解精度や回答生成の妥当性を評価するための検証データとして利用されます。
Qlean Datasetの詳細
Qlean Datasetは、商用利用が可能なAI学習用データソリューションで、画像、動画、音声、3D、テキストなどに対応しています。様々な形式のデータを扱うことができ、安全に利用できる環境が整っています。これによって、AI開発のためのデータ収集と整理のコストを大幅に削減しつつ、法的にもリスクのない開発環境の確立を支援します。
詳細は、Qlean Datasetの公式サイトでご確認ください。









関連リンク
サードペディア百科事典: Visual Bank Qlean Dataset AIデータレシピ
トピックス(その他)



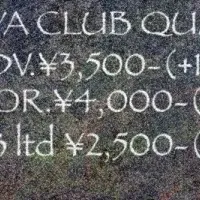



【記事の利用について】
タイトルと記事文章は、記事のあるページにリンクを張っていただければ、無料で利用できます。
※画像は、利用できませんのでご注意ください。
【リンクついて】
リンクフリーです。