




日本語LLMの革新に向けたAnoteの新プロジェクト開始
Anote, Inc.による日本語LLM革新プロジェクト
米国ニューヨークを拠点とするAnote, Inc.が、日本語の大規模言語モデル(LLM)に対する新しい評価・ファインチューニングプロジェクトを発表しました。このプロジェクトでは、会社や研究機関が参加できるパイロットプログラムが立ち上がります。
大規模言語モデルの現状と課題
AIの発展において言語モデルは重要な役割を果たしていますが、現在の多言語対応のLLMのデータセットは英語が圧倒的に多く、日本語は全体のわずか3〜5%を占めるに過ぎません。このデータの偏りが、日本語でのAI利用において重大な性能の低下を引き起こしています。Anoteのプロジェクトは、この議題に挑戦し、より優れた日本語AIの実現を目指しています。
プロジェクト概要と注目ポイント
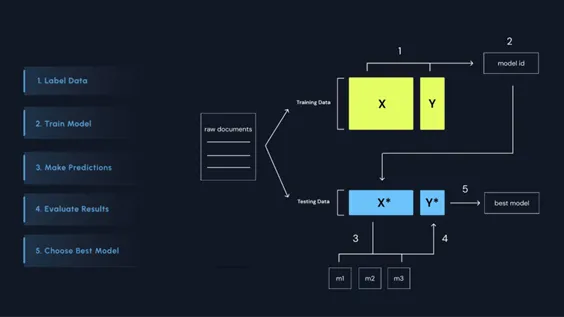
このプロジェクトは、Anoteが開発したエンドツーエンドのMLOpsプラットフォームが中心となります。このプラットフォームは、データアノテーションからファインチューニング、推論、評価、統合といった全てのプロセスをサポートし、誰もが人間中心型のAI開発にアクセスできる環境を提供します。具体的な特長は以下の通りです。
- - エンドツーエンドMLOps:アノテーションから統合までの全プロセスを一貫して支援。
- - マルチモデル比較:GPT、Claude、Llama3、Mistralなどのモデルと日本語データに基づくローカライズされたモデルの比較が可能。
- - 高度な評価フレームワーク:Cosine SimilarityやRouge-Lなど、複数の指標でモデルを多角的に評価。
- - 即時統合可能なAPI・SDK:ユーザーの環境に迅速にモデルを統合可能。
日本語LLMによるガイドライン
参加企業には、Anoteプラットフォームを利用することで日本語LLMの評価基準を策定し、高品質のトレーニングデータを生成してもらうことを目指しています。これにより、日本語NLPにおける初の公開型ベンチマークデータセットの構築が期待されます。
募集概要と参加手続き
本プロジェクトには、AIやLLMの開発に取り組む企業や研究機関が対象です。最大で5つの組織が選ばれる予定です。プロジェクト期間は2025年6月1日から10月1日までで、応募は2025年5月17日が締切です。
参加方法
参加希望の方は、Anoteの担当者へ直接メールして申し込むことが推奨されています。連絡先情報は以下の通りです。
- - Anote, Inc.(Natan Vidra 担当)
- Web: Anote Official Site
- - 日本国内パートナー(株式会社チャネルブリッジ)
- Web: チャネルブリッジ Official Site
この新しい試みによって、参加者は自社のデータを基にした最適化モデルの構築や、Japanese NLP向けのベンチマークデータセットへの貢献を果たすとともに、AI開発の未来を形作るための貴重な機会を得られるでしょう。

トピックス(その他)









【記事の利用について】
タイトルと記事文章は、記事のあるページにリンクを張っていただければ、無料で利用できます。
※画像は、利用できませんのでご注意ください。
【リンクついて】
リンクフリーです。